The Infinite Memory Architecture: How Nova "Remembers" 325 Billion Tokens
By Apollo Raines
In modern AI, "context window" has quietly become the new RAM limit. It decides how much an AI can keep in its head at one time, how far back it can look, and when it starts forgetting what just happened.
Most frontier models still live inside hard walls: GPT-4 hovers around 128K tokens, Claude 3 reaches about 200K, and Gemini can push to roughly 1M tokens. Those are impressive numbers -- but they are still ceilings. Once the window fills, something has to fall out the back.
Nova Omnis, my local crypto trading AI running on a single consumer GPU, breaks that ceiling in a different way. She is also my coding lab. She doesn't have a 325 billion-token context window, but she does have an effective memory footprint on that order -- because the architecture around her model treats storage, compression, and retrieval as first-class citizens.
This isn't magic. It's architecture. Specifically, it's the fusion of LoreToken Semantic Compression with SAIQL and its QIPI index -- a memory stack built to give a small model a training-set-scale recall surface.
To explain: SAIQL and QIPI are my not-free not-yet-released AI-native database and indexing pair, designed from the ground up for agents, not accountants.
SAIQL (Semantic Artificial Intelligence Query Language) is the engine. Instead of tables named orders and invoices, it stores things like episodes, regimes, trades, memories, and rules, all encoded as LoreTokens. It speaks a query language shaped around how an AI actually thinks. The language is agnostic, but remember she is a crypto trader, thus you will see crypto references in my explanations:
"Show me every BTC regime that looked like this volatility cluster,"
"Fetch the last 20 times Nova saw this pattern and how she responded,"
"Load all memories tagged {LIQUIDATION, CASCADE, WEEKEND}."
Under the hood, SAIQL blends row-store, column-store, and time-series patterns, but to Nova it just looks like: ask a semantic question, get back a compact symbolic answer.
QIPI v2 is the accelerator bolted onto SAIQL. Where normal databases lean on B-trees or hash indexes, QIPI uses a multi-layer probabilistic index tuned for LoreTokens and tags. Hot symbols (like BTC-USD, ETH-USD, or specific regimes) live in tiny, cache-resident "buckets" that can be hit in effectively O(1) time. A Bloom-style layer instantly rejects queries that have no matching data, and deeper sorted segments let QIPI skip 90%+ of the cold space on range queries.
The net effect is something existing stacks can't match:
- It's not a generic SQL database with vectors bolted on.
- It's not a pure vector store that only knows cosine similarity.
- It's a symbolic, tag-driven memory fabric where an AI can jump from "I see a pattern like March 2024" to the exact compressed episodes that matter -- across hundreds of billions of tokens -- without ever dragging the whole corpus into the context window.
That's how a local model, sitting on a single GPU, can behave as if it has training-set-scale recall instead of being trapped inside a 128K-token box.
The Problem: The Whiteboard Limit
Imagine an AI's working memory as a whiteboard.
A standard model writes everything in natural language: "The price of Bitcoin is $95,000." Ten tokens here, twenty tokens there. The more it writes, the faster that whiteboard fills. Once the context window is full, the model has no choice but to erase from the top to make room at the bottom. Yesterday's details disappear so today's sentences can exist.
That's the core limitation of most stacks today: more context means a bigger whiteboard. But a bigger whiteboard is expensive -- more VRAM, more bandwidth, more latency.
The Solution: Symbolic Semantic RAG
Typical Retrieval-Augmented Generation (RAG) systems try to dodge this limit with vector embeddings. They turn chunks of text into long lists of floating-point numbers and search those vectors with cosine similarity. It works, but it's fuzzy and expensive -- like trying to find a book in a library by describing how it made you feel rather than remembering the title.
Nova uses a different pattern: Symbolic Semantic RAG.
Symbolic means the data is stored as precise, compressed LoreTokens instead of raw sentences. Where a log line might say "The price of Bitcoin is $95,000," Nova can encode the same fact as something like ⟆₿:95k.
Semantic means retrieval is driven by meaning-level tags, not fuzzy vector proximity. A single memory might carry tags like {BITCOIN, ATH, BREAKOUT}, allowing Nova to search by concept and regime instead of paragraph position.
The result is a memory layer that has the precision of a database and the flexibility of an AI search engine -- without drowning in vector math.
1. LoreToken: The Language of Compression
Natural language is verbose. The sentence "The price of Bitcoin is $95,000" might be around ten tokens in a typical tokenizer. As a LoreToken, Nova can compress that same piece of information into a compact symbolic form such as ⟆₿:95k.
In practice, the compression ratio for real workloads averages around 2.6x. Roughly speaking, where 100 tokens of raw text would have been used, Nova can often represent the same information in about 38 LoreTokens.
On the whiteboard, that effectively triples the working area. A 128K context window behaves more like a ~332K window from a semantic standpoint. But that is only the size of the active desk -- not the full library.
2. SAIQL: The Infinite Library on SSD
When Nova's whiteboard fills up, she doesn't truly forget. She files. Older or less immediately relevant information is moved off the "desk" and into SAIQL -- the Symbolic AI Query Language and storage engine built around LoreTokens.
Underneath, this looks like a fairly ordinary hardware setup: a standard but dedicated 500 GB SSD, SAIQL managing the tables, and QIPI v2 (Quantum-Inspired Probabilistic Indexing) providing the index. The difference is how the data is stored and found.
QIPI organizes LoreTokens using probabilistic structures and semantic tags. A single record might be associated with tags like {BTC, PUMP, 2025} -- making it trivial to jump straight to "all Bitcoin pump events in 2025" without scanning the rest of the corpus. In practice, QIPI can locate a specific region of that 500 GB semantic space in a handful of microseconds.
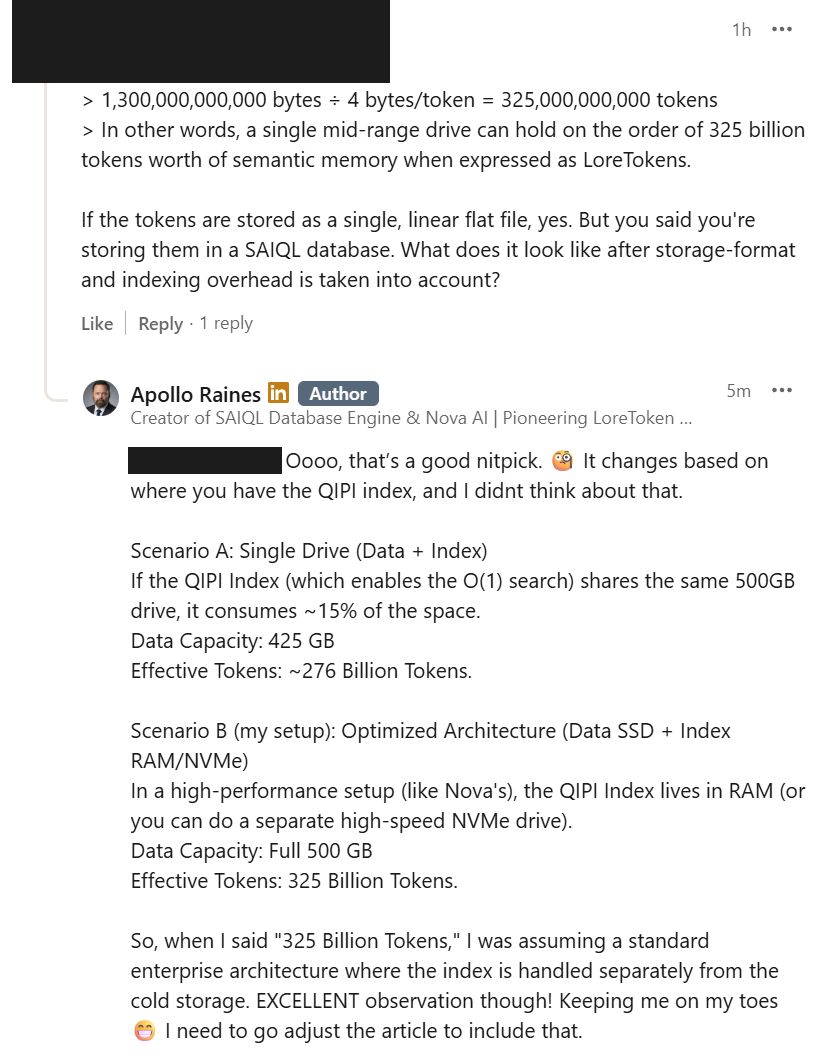
3. The Math: 325 Billion Tokens on a $50 Drive
So what does this look like in raw capacity terms? Take a perfectly ordinary 500 GB SSD -- the kind you can buy for around fifty dollars.
Stored as LoreTokens, real-world data tends to take roughly 38% of the space of its uncompressed text equivalent. That means 500 GB of LoreTokens can represent around 1,300 GB of raw text content at the semantic level.
Using the common rule of thumb that one token is approximately four bytes, that 1.3 TB equivalent works out to:
1,300,000,000,000 bytes / 4 bytes per token = 325,000,000,000 tokens
In other words, a single mid-range drive can hold on the order of 325 billion tokens worth of semantic memory when expressed as LoreTokens.
For perspective:
- The complete works of Shakespeare are roughly 1 million tokens.
- All U.S. federal laws together are on the order of a few hundred million tokens.
- The original GPT-3 training corpus has been estimated around the 300 billion token range.
On capacity alone, Nova's long-term memory layer can comfortably store a corpus in the same ballpark as a frontier-model training set -- backed by a single consumer SSD.
4. Workflow: The Desk vs. the Library
Nova doesn't try to keep 325 billion tokens in VRAM. That would require a rack of specialized hardware. Instead, she treats memory as two tiers: a fast desk and a deep library.
On the desk -- the active context window -- she keeps roughly 50,000 tokens of "hot" information in play. This is where live conversations, current market state, and immediate decision logic stay resident for fast reasoning. Next you will see why we limit it to 50k: bigger isn't better in this setup, it's the same.
In the library -- SAIQL on SSD -- she keeps everything else: historic trades, prior regimes, edge-case events, research notes, and symbolic summaries of past runs. This is the long-term semantic memory that lets Nova remember what happened months or years ago without dragging it all into VRAM.
When Nova encounters a pattern and needs deeper context, she doesn't guess. She asks the library: "Have I seen this configuration of volatility, volume, and sentiment before?"
QIPI responds by scanning the tagged, compressed corpus in microseconds, pulling back a small set of highly relevant LoreToken blocks -- for example, "the crash pattern from early 2024 under similar macro conditions." Those blocks are then expanded and placed onto the desk, where the model can reason over them just like any other context.
Conclusion: Bigger Windows vs Better Memory
Most of the industry is focused on stretching context windows: 128K, 200K, 1M, and beyond. Bigger whiteboards are useful, but they are also expensive, and they still fill up. At some point, you end up erasing something you may wish you had kept.
Nova's architecture takes a different direction: we don't just need bigger windows, we need better memory management. Symbolic compression via LoreTokens shrinks what needs to live on the desk. SAIQL and QIPI turn cheap SSD space into a massive, queryable semantic library. Together, they give a local AI the practical ability to "remember" on the order of hundreds of billions of tokens.
Nova is no longer limited by the token count in her model configuration. In practice, her recall is limited only by how many SSDs I choose to plug into the box.
Appendix: If LoreTokens Are This Compressive, Why Not Build a New Model?
If LoreTokens are so compressive, why not build a brand-new AI from the ground up that thinks in LoreTokens instead of JSON?
In theory, you absolutely could. In practice, training a frontier-scale model from scratch requires resources I don't have sitting under my desk. But we can still reason about what such a model would feel like compared to a traditional JSON/text-native model.
The core idea is simple: if your training data and runtime context are expressed in a format that carries more semantic information per token, then every unit of model capacity and every unit of context is doing more useful work.
LoreTokens don't magically change the raw parameter count. A 10B model is still a 10B model. What changes is how much structured meaning that model sees and can juggle per token.
Using a conservative 2.6x semantic density factor (100 tokens of raw text ~ 38 LoreTokens), a rough mental map looks like this:
- 10B LoreToken-native ~ feels like a 25-30B JSON/text-native model in useful semantic capacity per context window.
- 25B LoreToken-native ~ feels like a 60-70B JSON-based model on the same training token budget.
- 50B LoreToken-native ~ feels like a 125-140B JSON-based model.
- 100B LoreToken-native ~ feels like a 250-280B JSON-based model.
- ~400B LoreToken-native ~ starts overlapping with the behavior you'd expect from something in the 1T-parameter JSON regime.
"Feels like" means: for the same GPU and training budget, a LoreToken-native model sees more real structure per token (less punctuation, more meaning). For the same context window size, it can juggle more semantically relevant information at once, because fewer tokens are wasted on formatting. In tasks where the bottleneck is data efficiency and context density (not just raw network size), it will behave similarly to a much larger JSON/text-native model that's burning tokens on noise.
All of this is back-of-the-envelope theory, not a benchmark claim. Architecture, optimization, and data quality still matter as much as format.
A great question from the community:
If you accept the premise that semantic compression lets each token carry more meaning and less punctuation, then it follows that a model trained and operated in LoreToken space should consistently punch above its raw parameter count -- especially once it's paired with a memory stack like SAIQL + QIPI. One day I will accomplish this... one day.