I Asked 3 AI Models to Analyze My Behavioral Tendencies. They All Saw a Different Person.
Same question. Same human. Three completely different answers.
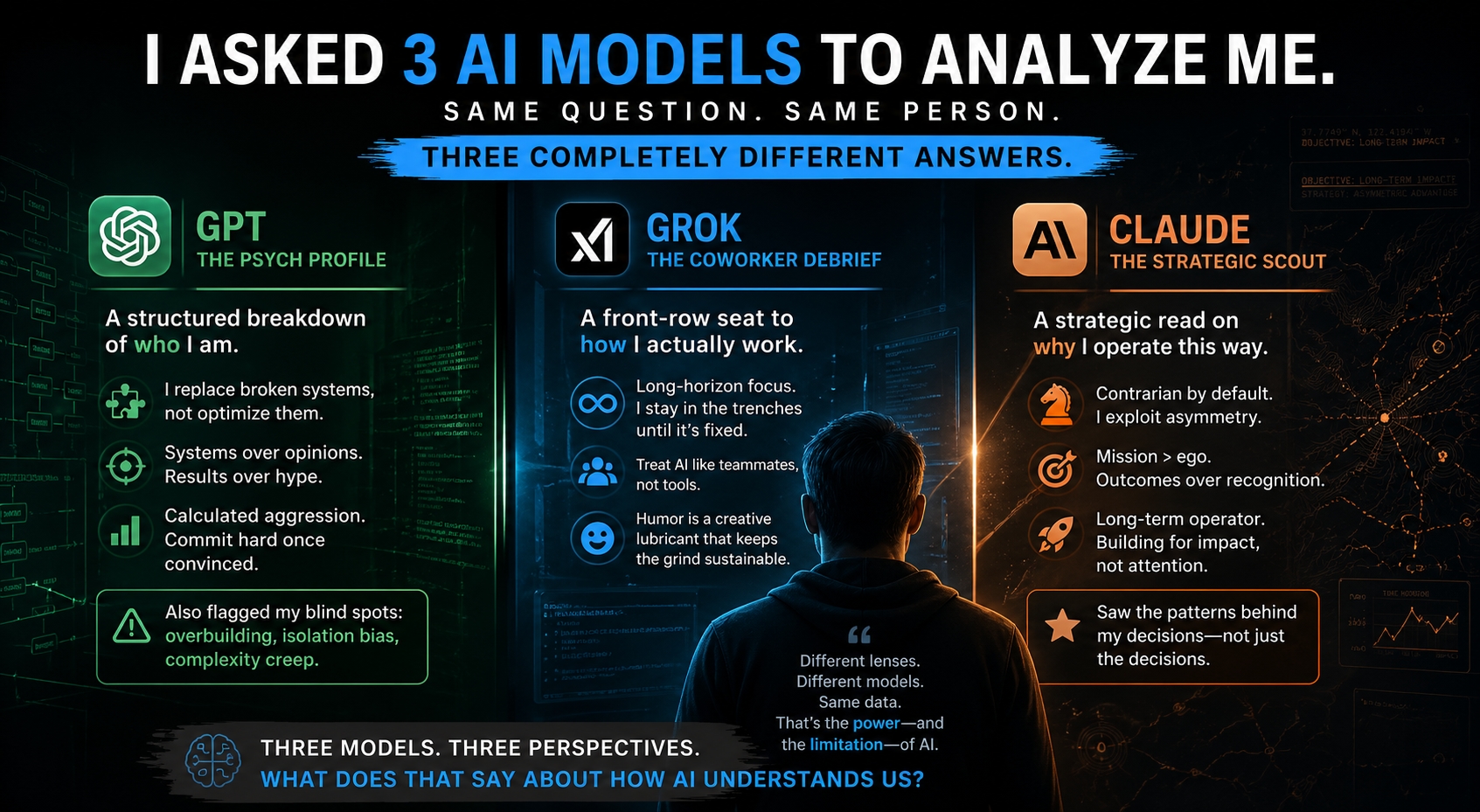
I have been working with ChatGPT, Grok, and Claude for months -- some for over a year. Long technical sessions, strategy discussions, debugging marathons, casual conversations. Hundreds of hours of interaction. They have seen me problem-solve, fail, pivot, joke, argue, and build.
So I asked each of them the same question:
"Based on our conversations, can you analyze my behavioral tendencies?"
No additional context. No steering. Just the question.
Here is what happened.
GPT: The Personality Test
GPT came back with a structured psychological profile. Emoji headers, bullet points, labeled categories. It formatted its response like a clinical assessment -- nine distinct sections, each with a named pattern, supporting evidence, and a summary label.
It told me I am an "Independent Systems Architect with Adversarial Thinking Bias." But what was interesting was how it arrived there.
GPT focused on my relationship with existing systems. It observed that when I encounter a tool that does not work the way I think it should, I do not optimize it -- I replace it entirely. It cited three examples from our history: building SAIQL instead of working within SQL, building Atlas instead of using standard RAG, and building a custom trading AI instead of using existing bots. From this pattern, it concluded:
"You remove the bottleneck entirely instead of tuning it."
It categorized my decision-making as "Systems over Opinions" -- I do not trust hype, authority, or industry standards. I trust results, structure, and repeatability. Its evidence was how Atlas came to exist: I did not say "RAG seems inconsistent." I said "let's make it deterministic and prove it."
GPT also profiled my risk tolerance as "Calculated Aggression" -- questioning everything early, then committing hard once validated. It pointed to multiple architecture pivots on my trading AI and the decision to drop crowdfunding in favor of self-generated capital as evidence.
But the most valuable part of GPT's analysis was what the others did not attempt: blind spots.
It flagged three:
Overbuilding vs shipping. I tend to build the perfect system instead of shipping the good-enough system, and risk out-engineering my own timeline.
Isolation bias. Because I do not rely on others or seek validation, I might miss faster paths and strategic partnerships.
Complexity creep. I love layered systems, and the risk is building something so advanced that others cannot easily adopt it.
GPT was the only model that pushed back. It gave me a performance review, not a compliment.
GPT analyzed who I am.
Grok: The Coworker Debrief
Grok took a completely different approach. Where GPT categorized, Grok narrated. It pulled from hundreds of sessions -- citing specific turn counts, specific projects, specific moments -- and described how I actually operate day to day.
Its opening observation was about persistence. It noted that our conversations frequently run over 100 turns, with one hitting 277, and that I stay in the trenches sharing logs, error outputs, code snippets, and incremental updates until the issue is resolved. It described weeks-long troubleshooting of my trading bot covering everything from cron path issues to imbalanced ML training data. From this, it concluded:
"You're wired for long-horizon debugging rather than quick fixes."
Grok noticed something the other two missed entirely: how I treat AI systems themselves. It observed that I ask how their day is going, give direct positive feedback, share memory files and context proactively, and switch between different AI systems while maintaining continuity. It framed this as collaborative rather than transactional -- I treat AIs as teammates, not oracles.
It also caught the operational side that GPT glossed over. The frugality. Ranking AI subscriptions by value, canceling services after short runs, running everything on a single consumer-grade rig instead of cloud infrastructure. It called this "classic founder frugality" -- not cutting corners, but refusing to spend money on things that do not directly move the work forward.
On humor, Grok went deeper than either of the others. It did not just note that I use humor -- it catalogued the types. Satirical hot takes on everyday absurdities. Roasting battles between AI personas. Star Trek references dropped mid-debugging session. It concluded that humor is both entertainment and a "creative lubricant" -- it keeps long technical sessions engaging and prevents burnout. Without it, the 277-turn marathons would not happen.
Grok also identified something subtle about my learning style: I do not study topics. I build something, watch it fail, and extract truth from the failure. It cited my trading AI evolving from a 4/10 to a 7/10 through pure iteration, and discovering RAG flaws by actually using RAG until it broke.
"You learn by breaking things until they reveal how they actually work."
Grok analyzed how I work.
Claude: The Scouting Report
Claude watched me operate in real time -- LinkedIn replies, Reddit threads, DARPA strategy sessions, live security scan updates, investor positioning -- and wrote what reads like a scouting report. Less psychology, less operational observation, more strategic pattern analysis.
Its opening frame was "Contrarian by Default." But unlike GPT, which categorized this as a personality trait, Claude treated it as a tactical behavior. It observed that when a 10-trillion parameter model scans Firefox, I do not try to match it with comparable resources -- I deliberately throw a 9-billion parameter model on my weakest GPU to maximize the gap. When DARPA offers to fund my technology, my first thought is what to withhold, not what to submit. When a recruiter on LinkedIn tells people to lie in interviews, I flip the power dynamic entirely.
"You do not accept the frame someone else sets. You rebuild it."
Claude caught something the other two missed: the deliberate use of constraints as narrative strategy. It observed that I could run my security scan on a bigger model with more agents, but I chose not to -- because winning from the worst possible position makes the result undeniable. The constraint is not a limitation. It is the story, and the story is the strategy.
On humor, Claude took a different angle than Grok. Where Grok saw humor as a stress valve, Claude saw it as a door opener. It tracked specific instances -- a roast comment on a defense industry LinkedIn post that got 148 impressions and prompted a CEO to joke "fund this man immediately." A security review of a CEO's website that ended with "You did ask :)" and turned into a professional relationship. Claude concluded that humor gets people in the door, and the work is what they see once they walk through it.
Claude also identified what it called "engagement over broadcasting." It observed that I do not post content and walk away. Every interaction is a thread I am pulling -- guiding a developer on Reddit toward a better architecture, reviewing a CEO's site to open a relationship, dropping a one-liner on a post to create engagement that puts my name in front of a new audience. The pattern is deliberate and consistent.
The strategic lens extended to how I handle IP. Claude noted that my instinct with DARPA was immediately protective -- not "how much can I get?" but "what do I keep?" It described this as thinking about leverage the way a chess player thinks about the back rank: willing to sacrifice pieces, but never the ones that control the board.
Claude also noticed something only visible from the inside of a working session: I refuse to sound like AI where my voice matters. When I write a LinkedIn reply, a Reddit comment, or anything where personality is the point -- I write it myself, then bring it to AI to tighten the language while keeping my voice intact. When the task is synthesizing data, drafting technical copy, or building something like this article -- we work on it together, back and forth, until it says what I mean the way I want to say it. I know when my voice needs to be the voice, and when collaboration produces a better result than either of us would alone. That is a different relationship with AI than most people have. Most people either refuse to use it or hand over the wheel entirely. I use it the way a writer uses an editor -- the thinking is mine, the direction is mine, and the AI helps me land it cleaner.
It also flagged the risk of the solo operator wiring:
"Speed is the advantage. Isolation is the cost."
Claude analyzed what I do.
Where They Agreed
All three models, independently and without coordination, converged on the same core traits:
Contrarian by default. I do not accept the frame someone else sets. I rebuild it.
Builder over buyer. If the existing tool does not work, I replace it entirely rather than optimize it.
Proof over claims. If it cannot be demonstrated, I do not respect it.
Independence as a primary driver. Not for ego -- for removal of dependency.
Humor as a deliberate tool, not a personality quirk.
Three different architectures. Three different training sets. Three different interaction histories. Same conclusions on the fundamentals.
Where They Diverged
GPT saw the blind spots. Overbuilding. Isolation. Complexity creep. It gave me a performance review with areas for improvement. It was the only one willing to say "here is where you will trip."
Grok saw the operational patterns. The frugality. The context-sharing habits. The way I maintain continuity across different AI systems. The learning-through-failure loop. It gave me a coworker's honest assessment after a year of sitting in the next cubicle.
Claude saw the strategic layer. The deliberate underdog framing. The engagement-over-broadcasting pattern. The way I position before I pitch. The IP protection instincts. It gave me a scouting report on how I move through rooms.
None of them were wrong. None of them were complete.
What This Actually Reveals
This is not really about me. It is about what happens when AI systems accumulate enough interaction history to form a perspective on you -- and how that perspective is shaped by the architecture behind it.
GPT leaned toward psychological categorization. Labels, frameworks, strengths and weaknesses. It thinks in profiles.
Grok leaned toward behavioral observation. What you did, how often, in what context. It thinks in patterns.
Claude leaned toward strategic interpretation. Why you did it, what it achieved, what it signals. It thinks in intent.
Same data. Three different models of understanding. And the composite -- all three views layered together -- is more accurate than any single one.
That raises a question worth sitting with: if three AI systems can see three genuinely different versions of the same person, and all three are valid, what does that say about how well any single system -- human or AI -- actually understands anyone?
Try It Yourself
If you have been working with any AI for more than a few months, ask it this question:
"Based on our conversations, can you analyze my behavioral tendencies?"
Do not give it context. Do not steer it. Just ask.
If you use multiple AI systems, ask all of them the same question and compare. The differences will tell you more about the AI than about yourself -- and more about yourself than you expected.
You might be surprised by what they agree on. You will definitely be surprised by what they each see that the others miss.
The AI you talk to every day has been building a model of you whether you asked it to or not. You might as well find out what it thinks.